
Building a CSV-to-schema mapper with LLMs at CatalogIt
How we turned a fragile prompt into a reliable ingest pipeline serving real customers.
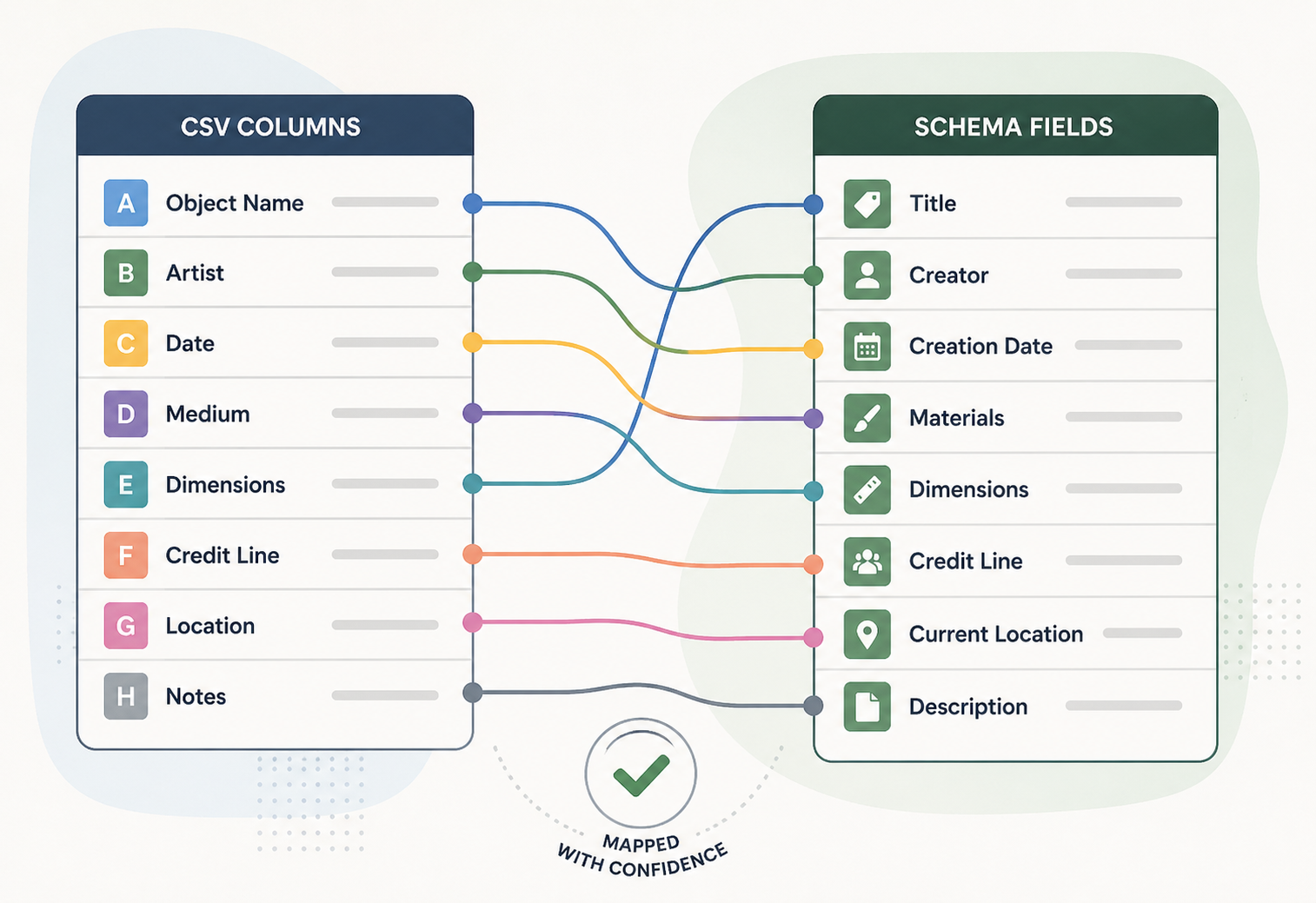
Most CatalogIt customers arrive with a spreadsheet. Sometimes well-formatted, often not. Our job is to land that data into the right places in the system — and we wanted to do it without a 30-minute onboarding call.
The problem
Museums, galleries, and private collectors arrive at CatalogIt with decades of records in spreadsheets. Column headers are inconsistent across institutions — “credit” might mean credit-line on one sheet and donor on the next. Some columns hold structured values (artists, materials) that need to be split into linked records; others are free text. CatalogIt’s schema has hundreds of properties across object types, and asking a curator to map every column by hand was the slowest part of onboarding.
The naive approach
The first POC (a closed PR from early on the project) was the obvious one: hand the LLM the entire CSV, the full schema, and ask for a complete mapping in one shot.
It worked often enough to be encouraging and rarely enough to be useless. The model would confidently map “credit” to a financial field, miss that “medium” and “materials” were the same concept across two sheets, or hallucinate properties that didn’t exist. There was no signal for how sure it was, no way to defer to a human, and no way to learn from past imports. Schemas with a few hundred properties also pushed the prompt long enough that quality degraded on the columns that appeared late.
The deeper issue: we were asking the model to do retrieval, classification, and reasoning all at once, with no structure to fall back on when any single step went wrong.
The pivot: per-column profiles + embedding search
We split the problem in two.
Step 1 — profile each column with the LLM, once. For each CSV column, we ask the model to produce a structured profile: the dominant data types, format patterns, semantic descriptors, and any other characteristics worth noting. This is a small, well-scoped task the model is good at.
Step 2 — match profiles to schema properties via embedding similarity. Every schema property has pre-computed embeddings (cached in Redis with a long TTL). For each column, we build three embedding queries from the profile:
- a header query — what the column is called and what it claims to be,
- a value query — what the data actually looks like,
- a context query — surrounding signals like neighboring columns and object type.
Each query is scored against the schema-property embeddings via cosine similarity, then combined with weights (header dominates, context refines, value disambiguates). A type-compatibility multiplier softly penalizes matches that don’t make sense (a date column shouldn’t map to a URL field). A structural-constraint filter removes candidates that can’t validly hold the column’s shape.
Three orthogonal signals turn out to be much more robust than one giant prompt — when the header is ambiguous, the values disambiguate; when the values are sparse, the context carries the column.
Layering with historical mappings
The AI suggestions don’t run alone. CatalogIt has a growing corpus of historical mappings from prior imports, and those win whenever they’re confident:
- Synthetic columns (CatalogIt’s internal fields) always resolve from history.
- Historical mappings above a high-similarity threshold short-circuit the AI entirely.
- For everything else, AI suggestions fill the gaps, and conflicts across sources are resolved with a priority rule.
This means the system gets quietly better as more customers import data, without retraining anything.
What’s in production today
The mapper runs in the import flow for both individual objects and bulk profile imports, typically resolving a full CSV in 15–30 seconds. The UI shows progressive status messages so curators know something is happening on longer files. If the AI step fails or times out, the import gracefully falls back to historical-only mappings rather than blocking the user. Every run writes a structured log for debugging the long tail of weird spreadsheets.
The biggest unlock wasn’t the model — it was giving the model a smaller, better-shaped job and letting deterministic systems (embeddings, history, type rules) handle everything else.